事例明确提出了下列难题,人们将其视作一切足球预测的标准规范:
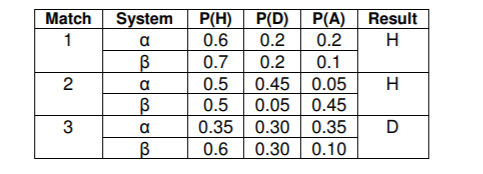
一、观查結果的预测值:在配对1中,α和β“恰当”特定较大值获得胜利几率(h)。
但人们是不是也应当充分考虑β的值更高,因而更形象化、更精确?
二、未观察几率的预测:针对配对2,系统软件α和β再度“恰当”分派
获得胜利几率较多(H)并且,她们不但分派同样的获得胜利結果的几率(均为0.5),他们也分派同样的几率值。
虽然与未观查到的結果不一样的次序(0.45和0.05)因此人们应当下结论α和β有同样的精确度假如人们那样干了,
这将违反一切足球比赛结果的判断力α比β更精确,由于平手比主客场更倾向于客场获胜。
三、不能观察概率分布:针对赛事3,2个系统软件都预测了平手几率0.3。
人们觉得这种预测是相同的还是应当考虑到不能观察几率的遍布判断力上α是优异的,
由于它的遍布几率比β更能表明平手,β能强有力地预测客场获得胜利。
例如人们觉得赛事的結果是0比1(客场0胜,主客场0胜)随后系统软件α造成均值为0.5的高方差遍布,
而系统软件β造成了一个低方差遍布,平均值偏向客场获得胜利。
四、总体目标差别:尽管結果简易地表达为H、D或A,但人们确实能承受的了忽视实际上的较后成绩?
假如主队以5比0获得胜利,这是不是使人们更相信实体模型β是在赛事1中好于α假如成绩是4-3,
人们是不是能够下结论α更精确?
五、红牌效用:假如一张或多个红牌早已对結果造成了明显的倾向时该怎么办比如,
在第三场赛事中,假如主队有一名足球运动员在上场比赛时被罚下,
这是不是代表实体模型β终归好于α?将会一些状况下坏的预测会看上去更强由于红牌效用。
当评定小量配对项?
为了便于BETSM准确性研究开展评定,对于他们开展了归类分成两类:
只考虑到对观查到的結果的预测(如信息内容损害);
及其这些充分考虑未观查到的結果和观查到的結果的预测(比如Brier得分);
人们从一些界定和假定刚开始足球预测是一切预测的充分必要条件,
一系列难题案例中每一个常有(固定不动的)有现个結果k的难题一个,
假定预测系统软件为每一难题案例中的每一結果分派几率值,
是预测系统软件预测第个結果的几率。人们也会假定,
针对每一难题案例,众所周知实际上观查結果几率的相匹配向量,
针对足球预测,人们干了一些非常简易的假定:
有关较终的成绩,这些科学研究工作人员用成绩来预测,
将会的結果做为点评的基本这是不是适合没有范围内,人们的关心只取决于预测,
而并不是预测是怎样造成的这一样适用几率是由权威专家得出的,而并不是实体模型。
由于在足球赛中主场优势的广泛必要性,及其有关先在观点地开展的赛事的统计数据,
人们不觉得先在观点地开展的赛事是在这一范围之内。
人们常说的评估器就是指为一切预测系统软件α特定的方式:获取精确的比赛结果。
特别注意的是,在人们考虑到的一些评定者中,本人精确度评分是一个独特的积累评分的状况,
因而界定后面一种就充足了依据这种假定,
评定者根据较为2个预测系统软件α和β分别的积累精密度,就能够较为他们在一组难题案例上评分。
以便得出所述假定的一个简易事例,假如人们想应用规范贝叶斯实体模型。
在这样的事情下,成绩仅仅假定实体模型是恰当的,观查统计数据的几率;
这称为概率。依据BETSM定理,假如人们沒有先验的原因假定一个实体模型是比另一个更恰当,
那麼造成较多概率的实体模型将会呈现更“恰当”的预测模式,
依据配对1,β被觉得比α更精确,由于它有更有将会变成“恰当”的实体模型针对2号和3号赛事,
实体模型或许是没法区别。
BETSM软件认为,在给出实体模型的状况下,观查一组配对結果的几率是恰当的。
{kind=link}